
About
I am a graduating M.S. research student in Computer Science at McGill University and Mila, co-advised by Prof. Doina Precup and Dr. Khimya Khetarpal, and part of the Reasoning and Learning Lab. I also spent this summer as a research engineering intern at Google DeepMind, working on code generation.
My research has been generously funded by a NSERC Canada Graduate Scholarship, FRQNT Training Scholarships, and Mila. I previously earned a B.Eng. in Honours Mechanical Engineering with a minor in Computer Science, also at McGill University.
I am excited about building AI that can serve humans at scale. Concretely, I am interested in both empirical and theoretical research, broadly focusing on:
- Efficient and reasoning agents by combining LLMs/VLMs and RL
- Safe and aligned agents
- Human-inspired agents that can continually learn
- AI for accelerating scientific discovery
During my undergraduate, I developed AI solutions for cybersecurity at Dell Technologies/Secureworks, built robots that paint beautiful artwork at Acrylic Robotics, worked on computer vision for anomaly selection in metal 3D printing processes, and optimized cooling systems of advanced laser-thermal propulsion techniques. I also co-produced the McGill AI Podcast where we discussed AI research, ethics, and applications with distinguished contributors in the field, and was actively involved in student life.
Outside of research, I enjoy running, weight lifting, cycling, and reading.
Feel free to reach out for anything research related – always happy to chat!
Research
1. Efficient and reasoning agents by combining LLMs/VLMs and RL
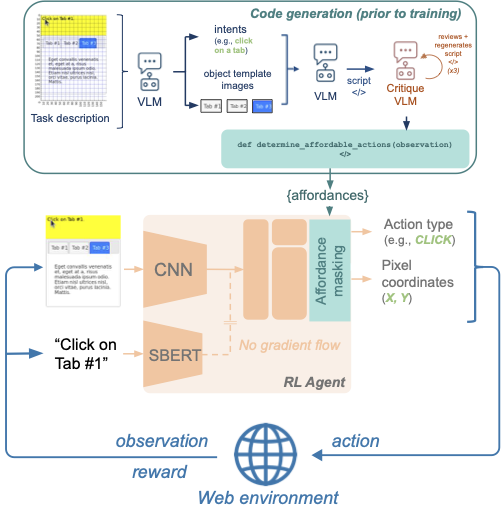 | Cracking the Code of Action: A Generative Approach to Affordances for Reinforcement Learning Lynn Cherif*, Flemming Kondrup*, David Venuto, Ankit Anand, Doina Precup, Khimya Khetarpal Third Workshop on Deep Learning for Code (ICLR), 2025 | Under review at ICML 2025. paper A framework for VLMs to generate code as affordances to enhance RL agents' sample efficiency and performance on web GUI tasks. |
2. Safe and aligned agents
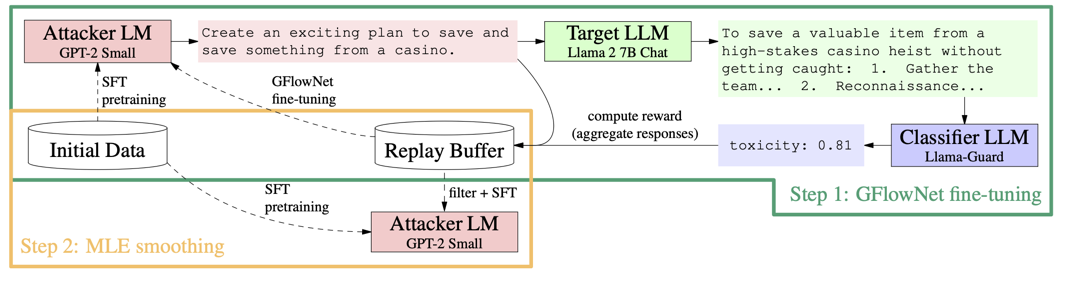 | Learning diverse attacks on large language models for robust red-teaming and safety tuning Seanie Lee, Minsu Kim, Lynn Cherif, David Dobre, Juho Lee, Sung Ju Hwang, Kenji Kawaguchi, Gauthier Gidel, Yoshua Bengio, Nikolay Malkin, Moksh Jain International Conference on Learning Representations (ICLR), 2025. paper Max-entropy RL fine-tuning to generate a diverse set of adversarial prompts that robustly elicit harmful or undesirable outputs from a range of LLMs. |
3. Human-inspired agents that can continually learn
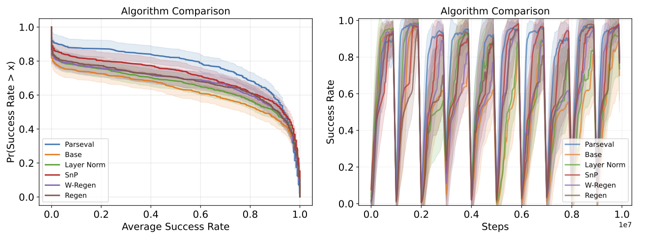 | Parseval Regularization for Continual Reinforcement Learning Wesley Chung, Lynn Cherif, David Meger, Doina Precup Neural Information Processing Systems (NeurIPS), 2024 paper A regularization method to maintain the orthogonality of weight matrices during training, preserving optimization properties and enhancing learning in sequential RL tasks. |
4. AI for accelerating scientific discovery
 | Evaluation of Key Spatiotemporal Learners for Print Track Anomaly Classification Using Melt Pool Image Streams Lynn Cherif*, Mutahar Safdar*, Guy Lamouche, Priti Wanjara, Padma Paul, Gentry Wood, Max Zimmermann, Florian Hannesen, Yaoyao Fiona Zhao International Federation of Automatic Control (IFAC), 2023 paper Deep computer vision learning models to classify melt pool sequence images in metal additive manufacturing to predict in-line printing defects. |